Решение проблем с индексацией новостного сайта в Google
Решение проблемы с индексацией многоязычного новостного сайта, который терял страницы из индекса на протяжении шести месяцев
Проект представляет собой новостную платформу посвященную мировым происшествиям и фактчекингу политических и социальных явлений. Платформа содержит множество страниц, поскольку на старте сайт поддерживал 8 языков, а теперь уже 11. Все материалы уникальны и написаны группой авторов. На сайте используется много тегов, и генерация контента с помощью ИИ не применяется. Проект обладает значительной ссылочной массой из новостных изданий по всему миру. Однако за последний год наблюдалось снижение поискового трафика и массовое выпадение страниц из индекса.
Найти и устранить причину проблем с индексацией страниц.
Стратегия
Клиент ранее не занимался продвижением сайта в поисковых системах, и весь SEO-трафик получал естественным образом. Точной информации о том, с какого момента Google начал исключать страницы из индекса, у клиента не было. Процесс шел постепенно на протяжении длительного времени, без резких скачков как в выпадении страниц, так и в падении трафика. Однако было заметно четкая ниспадающая динамика. На момент обращения в агентство в индексе оставалось менее 25% от общего количества страниц на сайте.
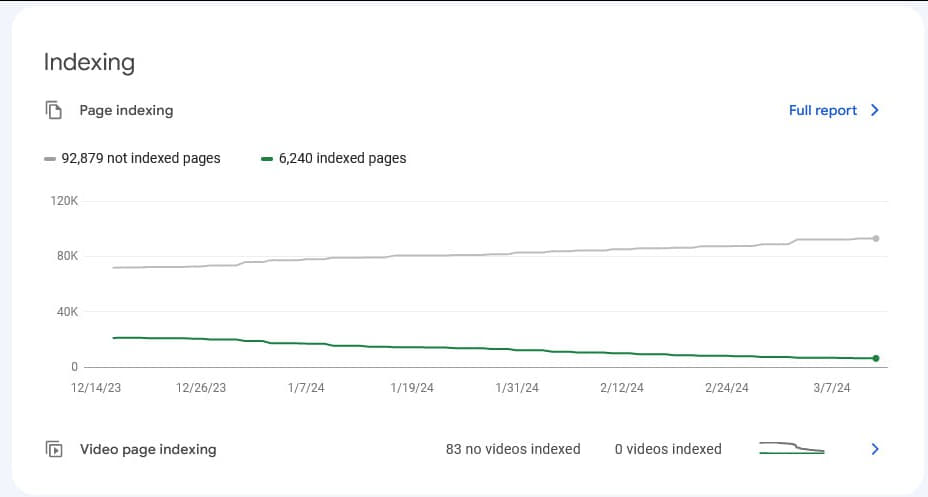
В конце 2023 года клиент обращался в одно из европейских агентств для проведения технического аудита. Однако на тот момент проблемы, которые наблюдаются сейчас, на сайте отсутствовали. Агентство предоставило рекомендации по исправлению технических ошибок, актуальных на момент того обращения, но было неясно, какую часть этих рекомендаций клиент в итоге внедрил. C тех пор сайт значительно расширился, и по сути, требовалось начинать технический анализ с нуля.
Стратегия работы
Согласно данным Google Search Console, причина выпадения страниц из индекса не была очевидна. В отчетах по индексации наблюдалось как появление новых URL в индексе, так и выпадение ранее проиндексированных страниц. При этом не было никаких признаков ручных фильтров или явных проблем с доступом Google к сайту. Google Pagespeed Insights и Google Microdata Checker без проблем обрабатывали страницы, включая те, которые выпали из индекса. Сайт был построен на WordPress, и страницы отдавались в Google в виде стандартного HTML-кода, что должно было способствовать успешной индексации, но на практике оказалось наоборот.
Технический аудит
В первую очередь мы провели анализ сайта на предмет технических ошибок, и их оказалось довольно много. В процессе аудита мы столкнулись с дополнительными сложностями.
- На сайте было огромное количество URL, и их все нужно было передать в программу для сканирования сайта. Это создавало большую нагрузку на сервер, и при достижении пороговых значений клиент был вынужден останавливать процесс.
- Дополнительно на сайте был настроен Cloudflare и защита хостинга от DDoS-атак, что также приводило к блокировке SEO-сканера. Поэтому было решено вносить правки на сайт поэтапно: дожидаться внедрения необходимых частей аудита, затем повторно сканировать и проводить аудит итерационно, так как из-за указанных проблем удавалось просканировать не более 10% сайта за раз.
Первичные результаты аудита
Редакторы проекта, публиковавшие контент, создавали в каждой статье множество внутренних ссылок на другие тематические страницы. Однако они не имели достаточных знаний о правильном формировании URL на сайте. В результате внутренние ссылки в статьях часто вели на:
- страницы внутреннего поиска по ключевым словам;
- другие разделы и страницы сайта, включая страницы с GET-параметрами, такими как `highlight`, `list` или `grid`, параметры сортировки и другие;
- страницы внутреннего поиска с GET-параметром, определяющим тип контента (сайт поддерживал несколько типов контента, и внутренний поиск осуществлялся отдельно для каждого типа через соответствующий GET-параметр);
- дублирующие страницы сайта без `/` в конце, которые являлись копиями оригинальных страниц.
Кроме того, на сайте было добавлено множество нестандартных функциональных элементов, которые теоретически могли оказывать влияние на его работу. Распутывание этого клубка проблем требовало поэтапного подхода, тем более что все затруднялось длительным процессом согласования с руководством проекта. Без их одобрения нельзя было вносить ни малейших изменений на рабочий сайт.
Первая итерация
В ходе анализа данных Google Search Console было обнаружено, что Google преимущественно исключает из индекса статьи с новостями и опровержения фейковой информации на тему ситуации в Украине (фактчекинг). При этом он индексирует множество дубликатов и страниц, закрытых от индексации.
Начальная гипотеза на этом этапе заключалась в том, что из-за большого объема “мусорного” контента на сайте (многочисленных ссылок на страницы, закрытые от индексации, и большого количества исходящих ссылок из публикаций) внутренний ссылочный вес сайта распределялся некорректно. В результате чего Google рассматривал многие страницы как некачественные и исключал их из индекса. Других предположений у нас не было, так как принудительная отправка страниц в индекс не давала результатов, несмотря на то что Google не имел к ним никаких явных претензий.
Поэтому в первой итерации было решено сначала исправить код всех публикаций на сайте, чтобы устранить ссылки на дублирующиеся и малополезные страницы. Поскольку такие страницы обычно обладали определенными характеристиками, ссылки на них можно было обнаружить в коде страницы. С помощью специального скрипта программисты просканировали весь сайт, обнаружили подобные URL и составили таблицу с правками для корректировки этих ссылок.
Затем другой скрипт заменил некорректные ссылки на правильные. Кроме того, весь функционал, который пытался отдавать боту ссылки на страницы с GET-параметрами отображения, сортировки и т.п., был заблокирован, чтобы бот их не видел при сканировании.
Эта правка позволила сократить количество URL, отдаваемых SEO-краулеру, и улучшить сканирование сайта. Также данное исправление повлияло на Google, который после этих изменений стал лучше индексировать полезный контент, и игнорировать нерелевантный.
Вторая итерация
Правки первой итерации не решили основную проблему проекта, однако позволили нам продвинуться дальше и приступить к следующему этапу работ.
Функционал тегирования
После повторного сканирования сайта стала очевидна еще одна проблема: владельцы проекта значительно видоизменили WordPress, заменив стандартный функционал тегирования на внутренний поиск, который был закрыт для индексации. Это означало, что у каждой статьи был целый ряд прикрепленных тегов в виде ссылок, ведущих на страницу внутреннего поиска с соответствующим запросом. При этом оригинальные страницы тегов для бота отдавались как пустые страницы с белым экраном через карту сайта.
Поэтому следующим шагом стало возвращение к исходной системе тегирования в WordPress, чтобы каждый тег на сайте представлял собой индексируемую страницу с четким URL без GET-параметров. Было принято решение отказаться от использования внутреннего поиска вместо тегирования.
Кнопки расшаривания контента
Кроме того, на сайте были встроены кнопки для расшаривания контента, включающие функционал копирования URL страницы для вставки в iframe на сторонних площадках. Этот функционал был внедрен с маркетинговой логикой, схожей с данной:

Однако этот функционал был реализован иначе: контент всех страниц публикаций дублировался на специальных облегченных страницах, закрытых от индексации, которые встраивались в iframe при использовании специального кода. Эти страницы можно было просматривать в полном объеме в маленьком окне прямо на сторонней площадке. Несмотря на запрет индексации, Google периодически индексировал такие страницы, тогда как основные аналогичные страницы оставались не проиндексированными.
Поэтому было решено отказаться от кнопки, которая предоставляла код для фрейма со ссылкой на облегченную версию страницы.
Переключение языков
Дополнительно на этом этапе было решено пересмотреть функционал переключения языков. Поскольку на сайте каждый язык имел разное количество публикаций, клиент использовал стандартный функционал переключения языков нестандартным образом. На каждую статью выводились ссылки на другие языковые версии. Блок переключения языков вел на те страницы, где был доступен перевод на соответствующий язык, а в случаях отсутствия перевода ссылки вели на главную страницу сайта на выбранном языке.
В результате, из-за расширения количества языков, в большинстве случаев языковой переключатель на многих страницах сайта ссылался именно на главные страницы других языков.
Этот функционал было решено переработать и закрыть в скрипт, чтобы боту не предлагались главные страницы на других языках. Тем более что главная страница проекта собирала весь трафик по брендовому запросу, а не по общим ключевым словам, важным для SEO.
В результате этой итерации количество проблемных точек на сайте уменьшилось, но основная проблема, с которой обратился клиент, все еще оставалась нерешенной.
Третья итерация
После двух этапов работы у нас возникла новая гипотеза: проблема может заключаться в шаблонах тех страниц, которые выпадают и не индексируются. Например, тип страниц “Публикация” выпадали из индекса, тогда как статичные страницы индексировались без проблем. Более того, страницы типа “Отчет” индексировались, даже если они содержали ошибку "Отчет не найден", поскольку такие страницы не возвращали серверный ответ 404, а выдавали 200 OK.
Проверка разных шаблонов
Было принято решение проверить предположение на практике. Была создана копия одной из публикаций, и на ней по очереди отключались разные элементы контента: блоки перелинковки, внутренние ссылки, изображения. Однако страница публикации, даже в облегченной версии с одним только текстом, так и не попала в индекс.
Поэтому было решено попробовать опубликовать контент одной из статей сайта с использованием другого шаблона. Мы взяли одну статью в виде чистого HTML и опубликовали ее не как обычную страницу в блоге (шаблон Post WordPress), а в шаблоне Page без каких-либо изменений в отображении. На этом этапе стало очевидно, что страница с шаблоном Page и контентом статьи, несмотря на неидеальное отображение, была проиндексирована. В то же время аналогичный контент в шаблоне Post не попал в индекс.
В обоих случаях Google не высказывал претензий к страницам и благополучно посещал их, что было видно в логах сервера.
Мы провели сравнение кода этих двух страниц, чтобы выяснить различия между версиями одной и той же страницы, но ничего существенного в коде обнаружено не было. Проверки Google также не выявляли никаких проблем с сайтом.
Проблемы со скоростью страниц
Было принято решение протестировать сторонние инструменты для анализа страниц и получения рекомендаций. Мы попробовали несколько вариантов, и только один из них показал необъяснимую проблему - при анализе двух версий одной и той же публикации SiteChecker выдал интересные результаты.
Страница на базе шаблона Page без проблем читалась этим инструментом, и система давала рекомендации по скорости, оптимизации кода страницы, подгружала метатеги и показывала вес страницы.
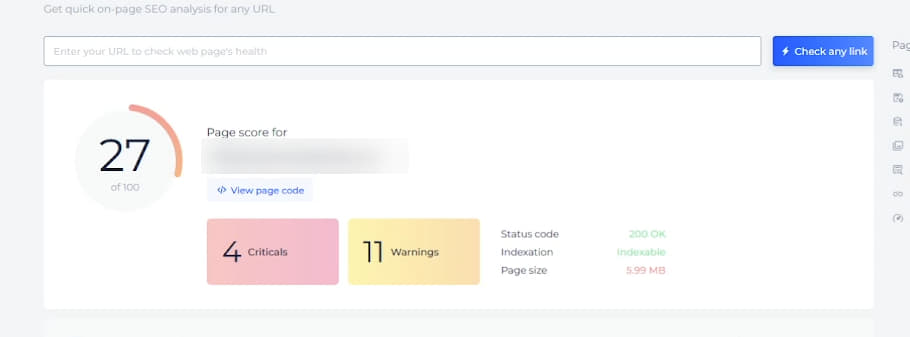
При этом страница шаблона Post, которая не индексировалась, показывала размер страницы 0, метатеги не подгружались, но при этом рекомендации по оптимизации скорости чекер выдавал:
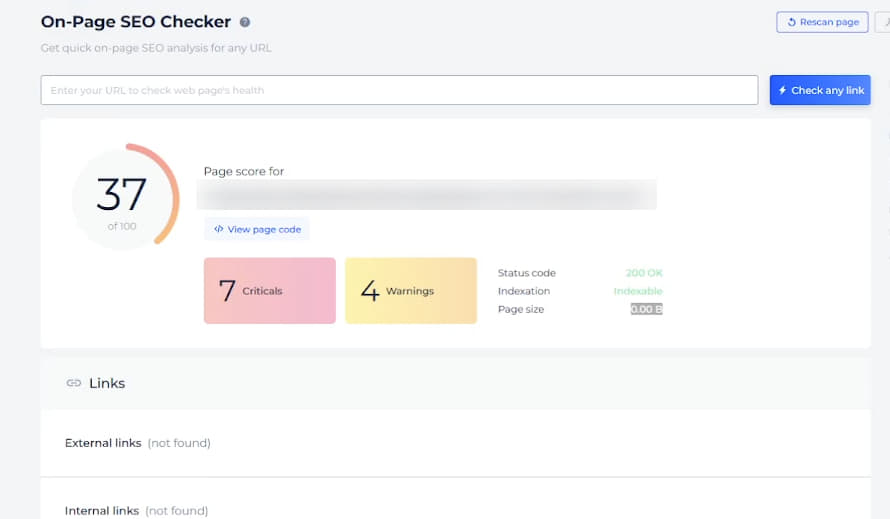
Причина подобного была непонятна и саппорт инструмента тоже не мог объяснить в чем причина такой проблемы
При анализе было замечено, что показатели скорости загрузки у страниц, использующих шаблон Page, и шаблон Post сильно различаются. Для страниц с шаблоном Post наблюдался высокий отклик сервера, что значительно снижало показатели скорости. На некоторых страницах статьи скорость по Pagespeed Insights была чуть более 20, а отклик сервера достигал 2-3 секунд, а иногда и больше.
Поэтому возникла гипотеза, что из-за низкой скорости загрузки страниц новостного сайта, особенно из-за длительного отклика сервера, Google возможно не дожидается полной передачи страницы и уходит. В связи с этим было решено максимально ускорить страницы, уделив особое внимание снижению времени отклика сервера и достижению хотя бы желтых показателей скорости по Pagespeed Insights.
Для этого была проведена работа с сервером, настройками облака Cloudflare и самим сайтом. Ради повышения скорости пришлось временно отключить часть функционала, чтобы разгрузить страницы, например, кнопки шаринга и блок подгрузки контента "Похожие публикации". Кроме того, были заменены плагины кэширования страниц и настроено многоуровневое кэширование, оптимизированы изображения, стили и скрипты.
В результате программистам проекта совместно с хостинг-провайдером удалось найти оптимальную конфигурацию среды для сайта и достичь более приемлемых показателей скорости:
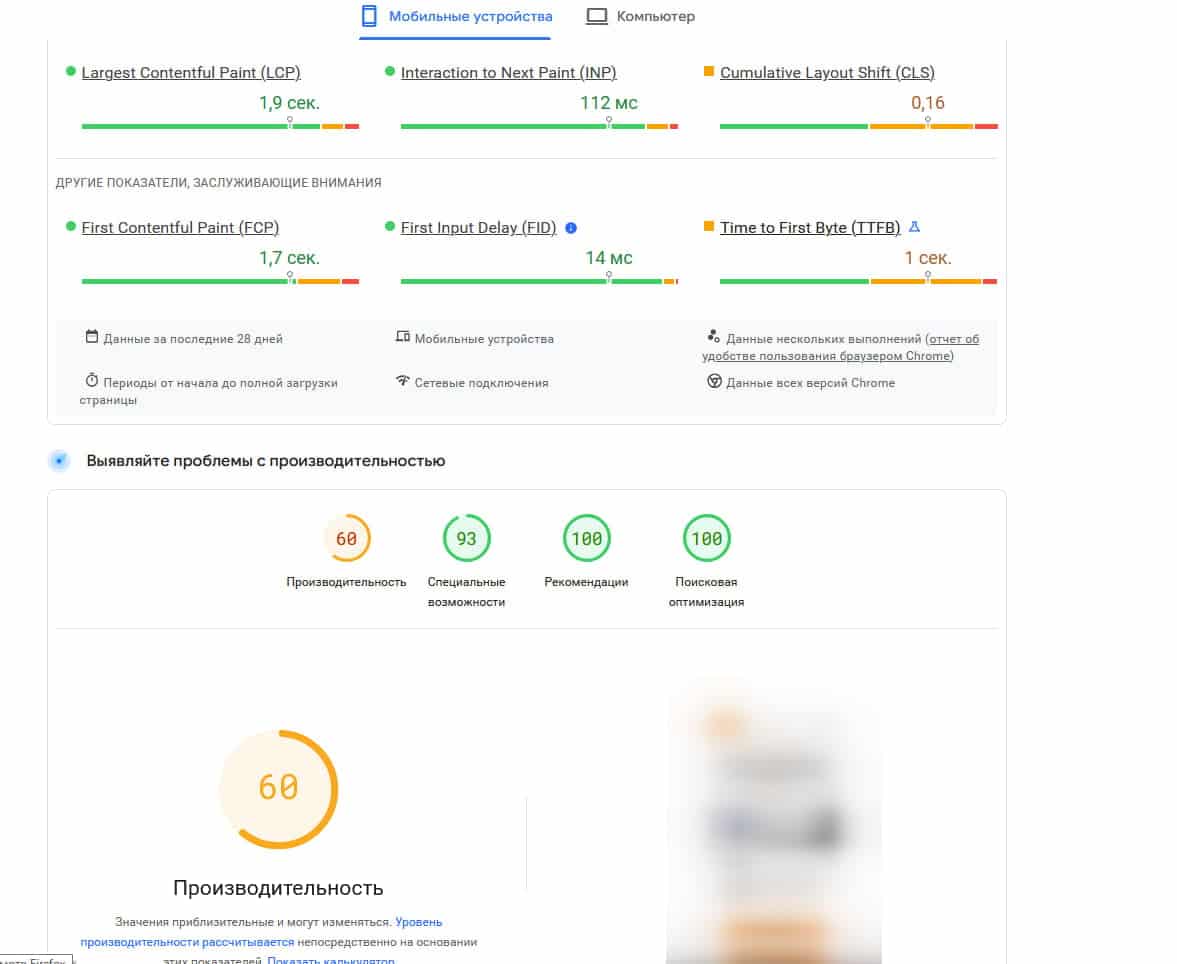
После этих исправлений удалось успешно проиндексировать несколько десятков страниц через Google Search Console. Однако спустя два выходных дня, когда было решено отправить на индексацию через Google Indexing API более значительное количество страниц, Google их в индекс не взял. Впоследствии он не принимал ни одну из следующих страниц, ни при ручной переиндексации, ни через API. При этом в Google Search Console снова не было никаких ошибок.
Четвертая итерация
На этом этапе мы продолжили работу с технической стороной проекта, в частности со скоростью страниц. Однако решили зайти немного с другой стороны.
Анализ кода и внутреннего функционала
Было решено сравнить код и внутренний функционал страниц которые попали в индекс, и аналогичных страниц, которые Google отказался брать в индекс.
По коду всё оказалось идентичным, за исключением части HTML-кода самой статьи. Программисты также подтвердили, что функциональных различий не было. Поэтому мы выбрали две страницы публикаций: одну, которая была в индексе, и другую, которая не была, и отправили их на анализ с помощью SiteChecker Free SEO Checker.
Отчет сервиса показал схожую картину: проиндексированные статьи без проблем скачивались и анализировались, а у не проиндексированных вес загруженной страницы оставался 0.
Проверка HTTP-заголовков тоже не выявила никаких отличий — они были идентичными для обеих страниц.
Мы проверили страницы также с помощью других анализаторов, которые в основном успешно проанализировали страницы и не выявили проблем, за исключением разницы в показателях скорости и времени отклика сервера, которые варьировались от страницы к странице. Возникла рабочая гипотеза, что сервер мог быть настроен не совсем корректно, что вызывает нестабильность отклика и проблемы с индексацией.
Однако, кроме скорости, чекеры не предоставили полезной информации, поэтому их результаты были в дальнейшем не учитывались.
На некоторые чекеры сработала защита Cloudflare или хостера, и сервер возвращал запрещающий ответ. Эти результаты также пришлось отбросить, так как аналогичных проблем у Google не наблюдалось, и на всех корректных страницах фиксировался отклик 200 OK.
Но один из чекеров, Pingdom Website Speed Test, показал очень странную картину, которую мы в агентстве не знали, как интерпретировать, и поэтому передали это на анализ программистам проекта. Страницы, которые успешно индексировались, имели вполне стандартный отчет:
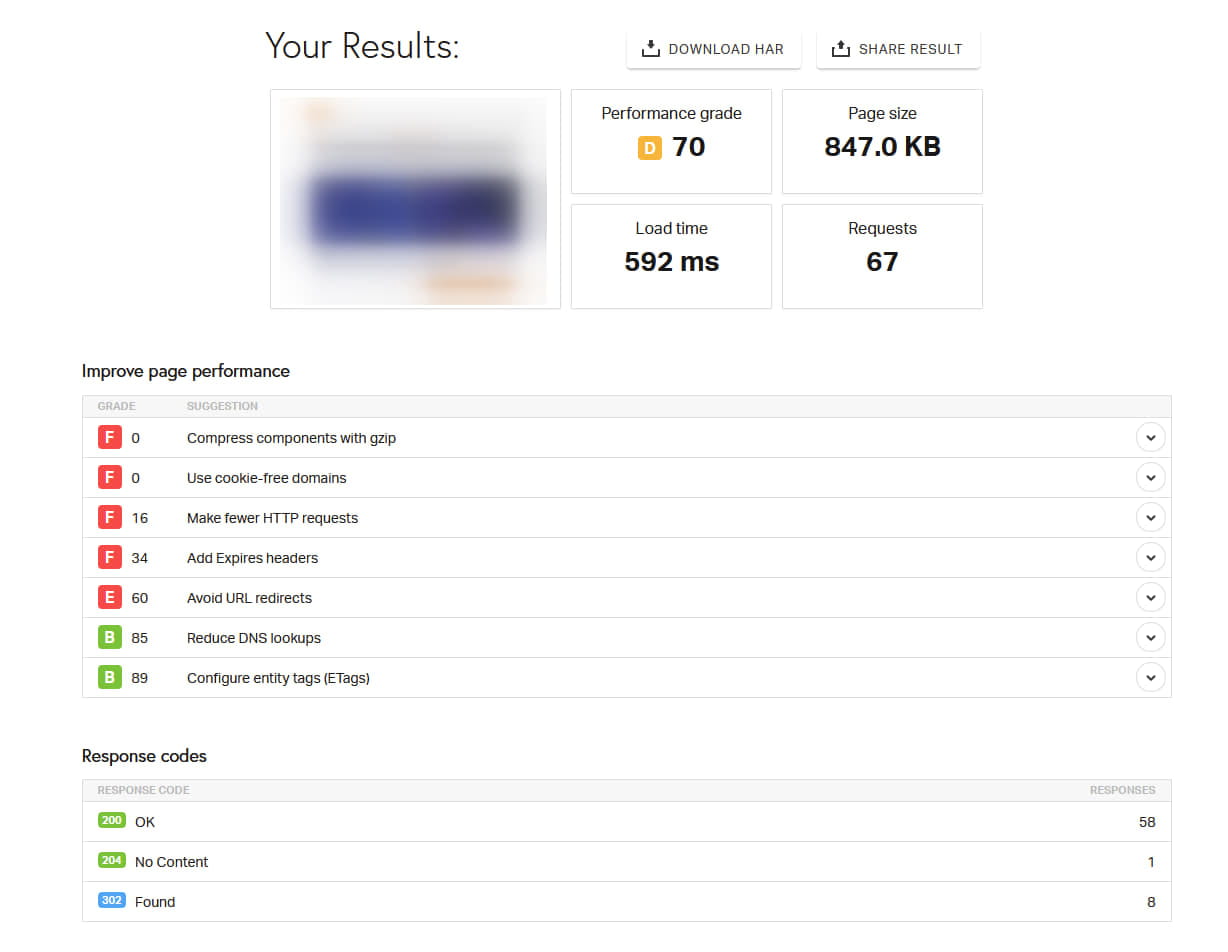
Здесь видны показатели загрузки, ответ сервера и скриншот страницы, которая загружается (он размыт слева вверху на скрине).
При этом страница, которая была не в индексе, не в индексе имела вот такой отчет:
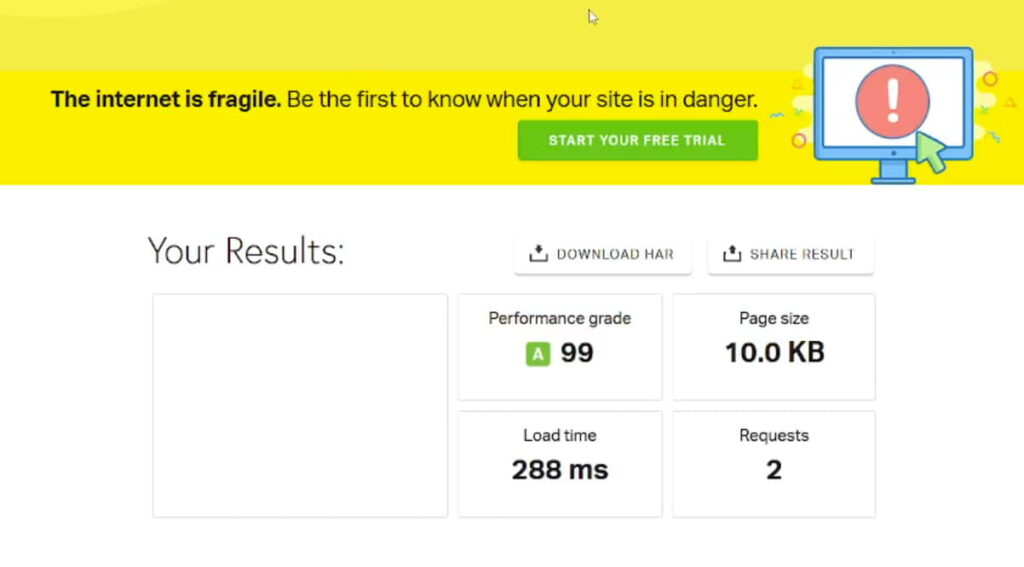
Система показывала очень маленький объем скачанной страницы и полностью пустой скриншот. При этом ниже в отчете сервер все равно отвечал 200 OK.
Это явно указывало на то, что страница, не попавшая в индекс, либо не отдавалась чекеру, либо передавалась некорректно. Причем проблема не была связана с сервером, а имела другие причины, которую мы не могли понять, так как не разрабатывали данную систему и не знали, что могло быть в коде.
Решение проблемы
Программисты начали детально разбираться в шаблоне страницы и искать, что могло, помимо серверных настроек и Cloudflare, мешать корректной отдаче страницы. В итоге они обнаружили, что в шаблоны страниц “Публикаций” были внедрены элементы поисковой системы Elasticsearch, которая была интегрирована для улучшения работы внутреннего поиска на сайте.
У этой системы есть своя защита от ботов и система фильтрации, которая избирательно срабатывает на некоторых ботах, возвращая белый экран вместо контента страницы, при этом сохраняя ответ сервера 200 OK.
Именно эта защита блокировала индексацию страниц для бота Google, в то время как Pagespeed Insights, Google Microdata Checker и краулер Google (который проверяет доступность страницы) проходили без проблем.
Так как решение об отдаче страницы принималось на бэкэнд-стороне сайта, подобную ошибку было невозможно обнаружить простым сравнением разных типов страниц. Нужно было столкнуться с ней в работе, чтобы система распознала запрос к странице как бота и отдала некорректную страницу.
Элементы поисковой системы Elasticsearch, которые мешали загрузке страниц, были внедрены только в определенные шаблоны контента, такие как Отчет и Post. В шаблонах категорий постов, статичных страницах и тегах этот элемент отсутствовал, поэтому они не выпадали из индекса, а напротив, индексировались по мере удаления дубликатов, ссылок на закрытые для индексации страницы и т.п.
После того как программисты устранили эту проблему, страницы начали индексироваться достаточно быстро. Исправление повлияло не только на статьи сайта, но и на раздел опровержения фейковых новостей, где была аналогичная проблема.
Результаты работы
На момент начала аудита у клиентского сайта было 6240 страниц в индексе, и они постепенно выпадали. В индексе не оставалось ни одной статьи, а те отчеты по фактчекингу, которые еще изредка попадались, содержали ошибку "Отчет не найден" и фактически были дубликатами страницы с этой ошибкой. В процессе работы, и поэтапного внедрения правок количество страниц не в индексе медленно уменьшалось и достигло 2711.
Однако, как только была обнаружена и устранена основная ошибка, процесс индексации значительно ускорился.
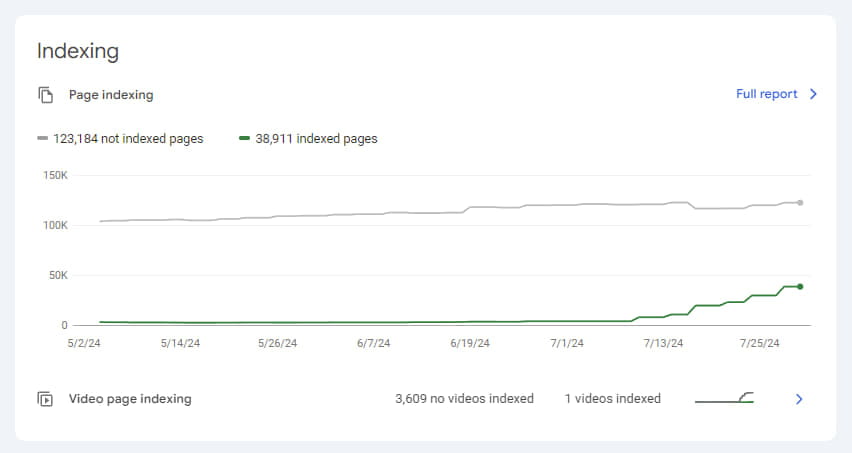
Чтобы дополнительно ускорить индексацию, мы использовали Google Indexing API, и менее чем за месяц нам удалось увеличить количество проиндексированных страниц с минимального уровня в 2701 до 38911. Это также положительно сказалось на трафике.
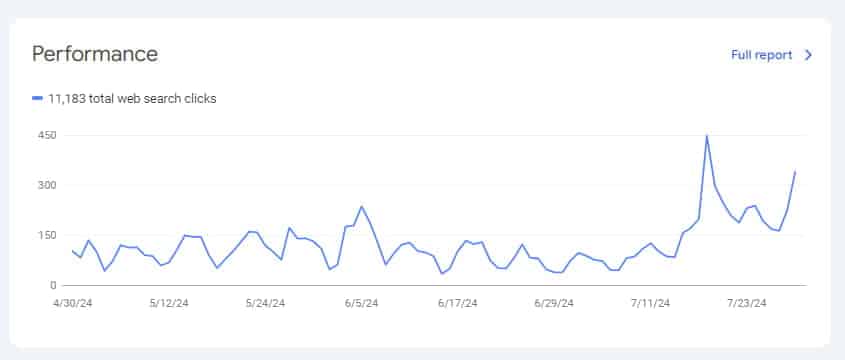
Конечно, процесс индексации проекта еще продолжается и займет некоторое время, но уже видно, что основная проблема, мешавшая индексации, была устранена.
Этот кейс наглядно демонстрирует, насколько важно глубокое техническое понимание и внимательный подход к анализу проблем с индексацией сайтов. Столкнувшись с нестандартной ситуацией, где привычные методы диагностики не выявляли проблем, наша команда сумела определить корневую причину благодаря последовательному подходу и поэтапному решению проблем.
Наш опыт подтверждает, что даже самые сложные проблемы можно решить при тщательном анализе, настойчивости, командной работе и правильном выборе инструментов.