Successful solving of Google indexing problems of the news website
Solving the indexing problem of a multilingual news website that was losing pages from the index over six months
The project is a news platform dedicated to world events and fact-checking of political and social phenomena. Since in the beginning the site supported 8 languages, and now it supports 11, the platform contains multiple pages. All materials are unique and written by a group of authors. The site has a lot of tags and content generation with AI is not used. The project has a significant amount of backlinks from news sources around the world. However, over the past year, there has been a decline in search traffic and a massive drop in pages from the index.
to find and get rid of the cause of the page indexing problems.
Strategy
The client did not optimize the site for search engines. and all traffic was natural. They also couldn’t tell when Google began banning pages from the index. The process was gradual over a long period, with no sudden jumps in page drop or decrease in traffic. However, there was a clear downward dynamic. At the time of contacting the agency, less than 25% of the total number of pages on the site remained in the index.
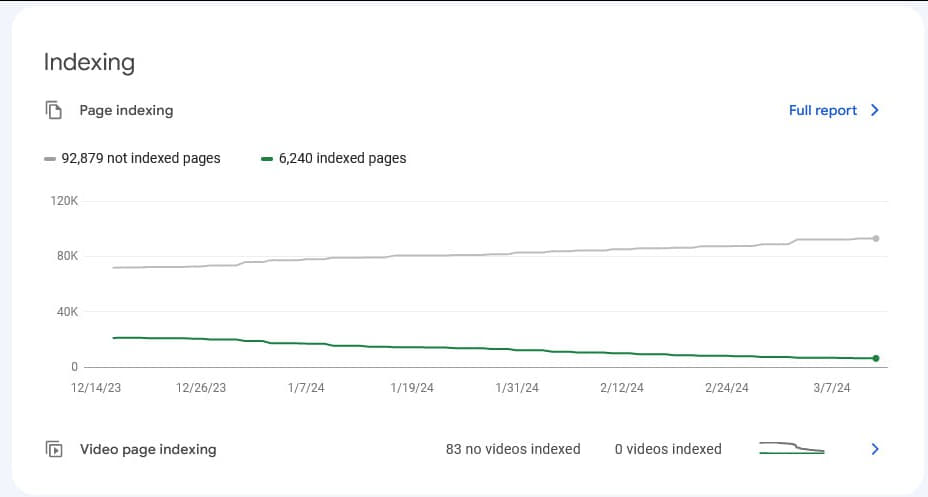
The client contacted a European SEO agency for a technical audit at the end of 2023. At that moment, the issues being identified now were not present on the site. The agency provided recommendations to fix the technical issues relevant at the moment of the request, but it was unclear how many of these recommendations the client ultimately implemented. Since then, the site has grown considerably, and it was essentially necessary to start the technical analysis from scratch.
Work strategy
Based on Google Search Console data, the cause of pages dropping out of the index was not clear. Indexing reports showed both new URLs entering the index and previously indexed pages dropping out. Meanwhile, there were no signs of manual penalty or clear problems with Google's access to the website. Google Pagespeed Insights and Google Microdata Checker processed all the pages without any issues, even those that had dropped out of the index. The site was built on WordPress, and the pages were submitted to Google as standard HTML code, which should have contributed to successful indexing but, in practice, had the opposite effect.
Technical Audit
First, we analyzed the site for technical errors and found a lot. During the audit, we faced additional challenges.
- The site had an enormous number of URLs, all of which needed to be sent to the site scanning program. This task loaded the server heavily, and when the threshold was reached, the client had to stop the process.
- Additionally, the site was configured with Cloudflare and hosting protection against DDoS attacks, which also led to the SEO scanner being blocked. Therefore, we decided to make changes to the site in stages: wait for the implementation of necessary parts of the audit, then rescan and audit it iteratively, as due to these issues, we could scan no more than 10% of the site at a time.
Initial Audit Results
The project editors who published content created numerous internal links in each article to other thematic pages. Unfortunately, they didn't have the appropriate knowledge to make the right website URL. Consequently, internal links in articles often led to:
- Pages of keywords internal search results;
- Other site sections and pages, including pages with GET parameters as 'highlight', 'list', or 'grid', sorting parameters, and others;
- Internal search pages with a GET parameter defining the content type (the site supported several content types, and internal search was performed separately for each type using the corresponding GET parameter);
- Duplicate site pages without a trailing '/', which were copies of the original pages.
Moreover, many non-standard functional elements were added to the site, which could theoretically affect its performance. Untangling this tangle of problems required a step-by-step approach, especially since the lengthy approval process with project management hindered everyone. Without their consent, we couldn't make any changes to the live site.
First Iteration
During the analysis of Google Search Console data, we found that Google was mostly excluding news articles and debunking fake information about the situation in Ukraine (fact-checking) from the index. At the same time, it was indexing numerous duplicates and pages blocked from indexing.
Our initial hypothesis was that due to the large amount of "junk" content on the site — many links to pages blocked from indexing and a lot of outbound links from publications — the site's internal link equity was being distributed incorrectly. As a result, Google considered many pages low-quality and excluded them from the index. We had no other assumptions, as forcing pages into the index showed no results, even though Google had no apparent issues with them.
Therefore, in the first iteration, we decided to fix the code of all publications on the site to eliminate links to duplicate and low-value pages. Since such pages usually had certain characteristics, links to them could be found in the page code. Using a special script, programmers scanned the entire site, identified such URLs, and compiled a table with corrections to adjust these links.
After that, another script replaced incorrect links with correct ones. Additionally, all functionality that tried to send the bot links to pages with display, sorting, and other GET parameters was blocked so that the bot wouldn't see them during scanning.
This correction reduced the number of URLs transferred to the SEO crawler and improved site scanning. This fix also affected Google, which began to index valuable content better and ignore irrelevant pages.
Second Iteration
Although the fixes from the first iteration did not solve the project's main problem, they allowed us to move forward and proceed to the next stage.
Tagging Functionality
After rescanning the site, another problem became obvious: the project owners had considerably modified WordPress, replacing the standard tagging functionality with an internal search that was blocked from indexing. These alterations meant that each article had a set of attached tags as links leading to internal search pages with corresponding queries. Meanwhile, the original tag pages were transferred to the bot as empty pages with a white screen through the sitemap.
Therefore, the next step was to return to the original tagging system in WordPress so that each tag on the site would be an indexable page with a clear URL without GET parameters. It was decided to abandon the use of internal search instead of tagging.
Content Sharing Buttons
What is more, the site had integrated content-sharing buttons with functionality to copy the page URL for embedding in an iframe on third-party platforms. This functionality was implemented with marketing logic similar to the following:

However, this functionality was performed differently: the content of all publication pages was duplicated on special lightweight pages blocked from indexing, which were integrated into an iframe using special code. These pages could be viewed in full in a small window directly on a third-party platform. Despite the Noindex directive, Google periodically indexed such pages, while the main equivalent pages remained unindexed.
Therefore, the button that provided code for an iframe linking to the lightweight version of the page was removed.
Language Switching
At this stage, we also decided to revise the language-switching functionality. Since each language on the site had a different number of publications, the client used the standard language-switching functionality in a non-standard way. Each article displayed links to other language versions. The language switcher led to pages where a translation was available, and in cases where there was no translation, the links led to the site's main page in the selected language.
Due to the expansion of languages, the language switcher on many pages referred to the main pages of other languages.
It was decided to rework this functionality and encapsulate it in a script so that the bot would not be offered main pages in other languages. Especially since the project's main page gathered all traffic through branded queries rather than general keywords important for SEO.
As a result of this iteration, the number of problematic areas on the site decreased, but the main issue the client approached us with remained unresolved.
Third Iteration
After two stages of work, we had a new hypothesis: the problem might lie in the templates of the pages that were dropping out and not being indexed. For example, pages of the "Publication" type were excluded from the index, while static pages were indexed without issues. Moreover, pages of the "Report" type were indexed even if they contained a "Report not found" error because such pages did not return a 404 server response but gave a 200 OK.
Testing Different Templates
We decided to test this assumption in practice. A copy of one of the publications was created, and various content elements — interlinking blocks, internal links, and images — were successively disabled. However, the publication page, even in a simplified version with only text, still did not get indexed.
Therefore, we decided to try publishing the content of one of the site's articles using a different template. We took an article in pure HTML and published it not as a regular blog page (WordPress Post template) but as the Page template without any display changes. At this point, it became clear that the page with the Page template and the article's content, despite imperfect display, was indexed. At the same time, the same content made with the Post template was not indexed.
In both cases, Google had no complaints about the pages and visited them successfully, as seen in the server logs.
We compared the code of these two pages to find differences, but nothing significant was found. Google's checks also did not reveal any issues with the site.
Page Speed Issues
We decided to test third-party tools for page analysis and get recommendations. We tried several options, and only one of them showed an inexplicable problem — when analyzing two versions of the same publication, SiteChecker provided interesting results.
This tool read the page based on the Page template without problems. The system gave recommendations on speed and code optimization, loaded meta tags, and showed the page weight.
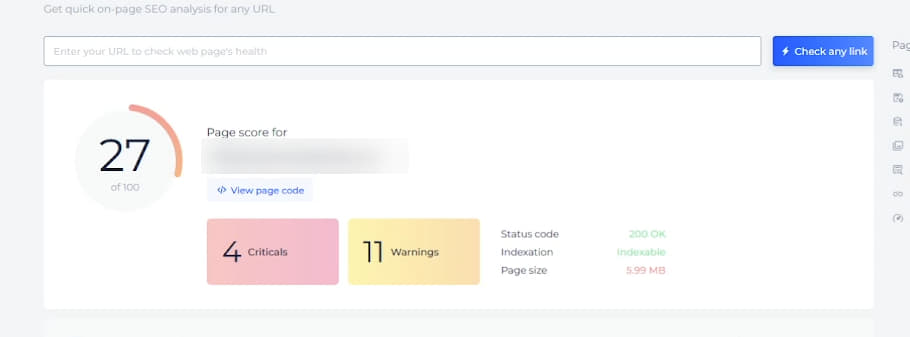
At the same time, the Post template page, which was not indexed, showed a page size of 0; meta tags were not loaded, yet the checker still provided recommendations for speed optimization:
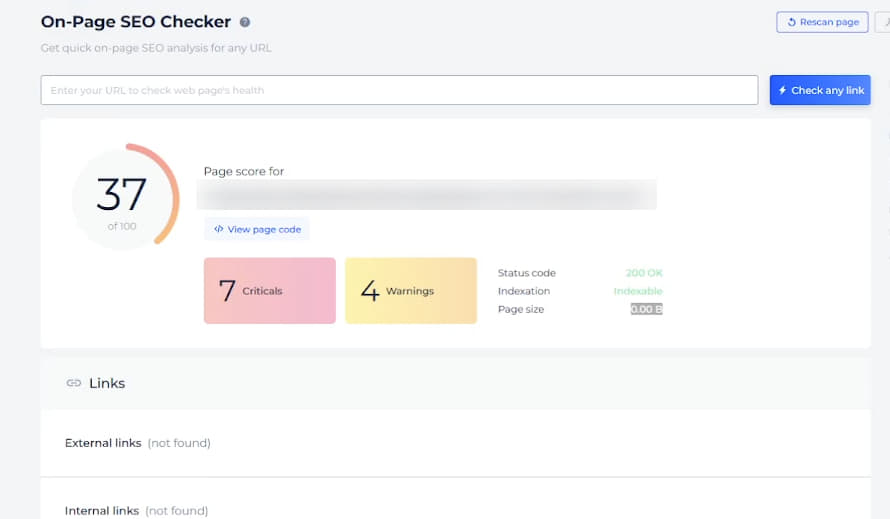
The reason for this was unclear, and the tool's support couldn't explain the cause of such an issue.
During the analysis, it was noticed that the loading speed indicators for pages using the Page template and the Post template differed significantly. For pages with the Post template, there was a high server response time, which significantly reduced speed indicators. On some article pages, the PageSpeed Insights score was just over 20, and the server response time reached 2–3 seconds or more.
A hypothesis arose that due to the low loading speed of the news site's pages — especially because of the long server response time — Google might not wait for the full page load and leave. We decided to maximize page speed, focusing on reducing server response time and achieving at least moderate speed indicators in PageSpeed Insights.
Proper work was done on the server, Cloudflare settings, and the site itself to achieve the abovementioned. To increase speed, we temporarily turned off some functionality to lighten the pages, such as sharing buttons and the "Related Publications" block. Additionally, page caching plugins were replaced, multi-level caching was configured, and images, styles, and scripts were optimized.
As a result, the project's programmers, together with the hosting provider, managed to find the optimal environment configuration for the site and achieve more acceptable speed indicators:
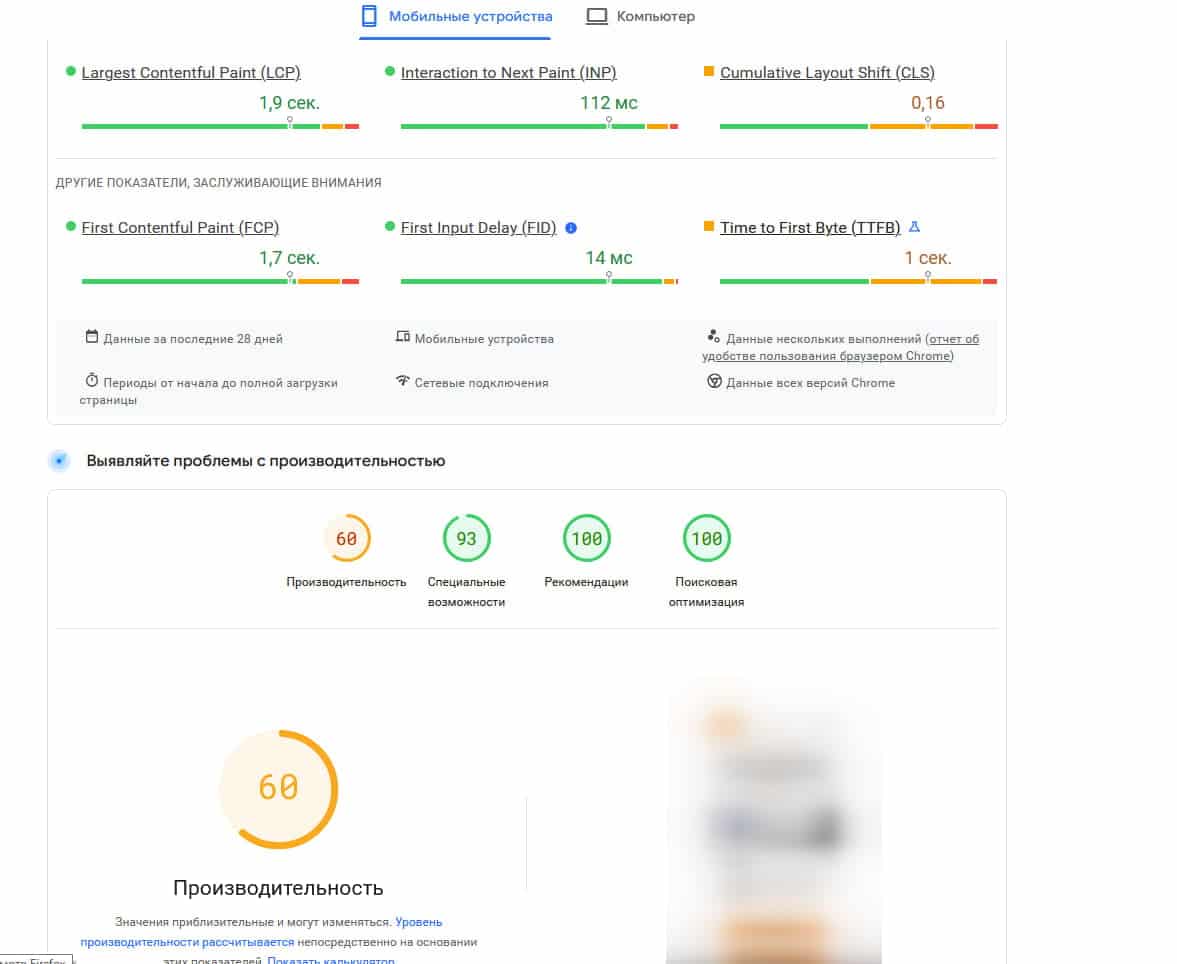
After these fixes, we successfully indexed several dozen pages through Google Search Console. However, after two weekend days, when we decided to send a larger number of pages for indexing via the Google Indexing API, Google did not index them. Afterwards, it did not accept any of the following pages, neither through manual reindexing nor via the API. At the same time, there were still no errors in Google Search Console.
Fourth Iteration
At this stage, we continued working on the project's technical issues, particularly on page speed. However, it was decided to give it another go.
Analysis of Code and Internal Functionality
We compared the code and internal functionality of pages that were indexed and similar pages that Google refused to index.
The code turned out to be identical, except for part of the article's HTML code. The programmers also confirmed that there were no functional differences. Therefore, we selected two publication pages, one in the index and another not, and sent them for analysis using the SiteChecker Free SEO Checker.
The service's report showed a similar picture: indexed articles were downloaded and analyzed without issues, while the unindexed ones had a downloaded page weight of 0.
Checking the HTTP headers did not reveal any differences — they were identical for both pages.
We also checked the pages using other analyzers, which mostly successfully analyzed the pages and did not reveal problems, except for differences in speed indicators and server response time, which varied from page to page. A working hypothesis emerged that the server might not be configured correctly, causing response instability and indexing issues.
However, apart from speed, the checkers did not provide useful information, so their results were not further considered.
For some checkers, Cloudflare or the hoster's protection triggered, and the server returned a forbidden response. These results also had to be discarded since Google did not have similar problems, and all correct pages recorded a 200 OK response.
But still, one of the checkers, Pingdom Website Speed Test, showed a very strange picture that we did not know how to interpret, so we passed it on to the project's programmers for analysis. Pages that were successfully indexed had a quite standard report:
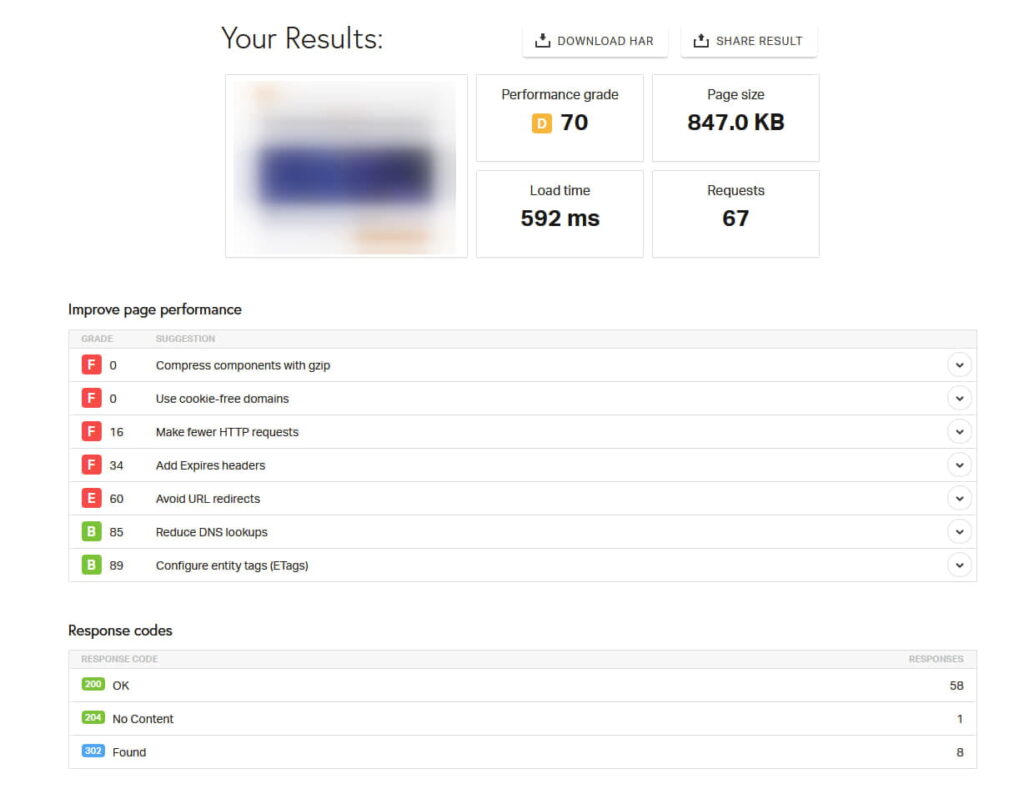
Here, you can see the loading metrics, server response, and a screenshot of the loading page (it is blurred in the top left corner of the screenshot).
At the same time, the page that was not in the index had this report:
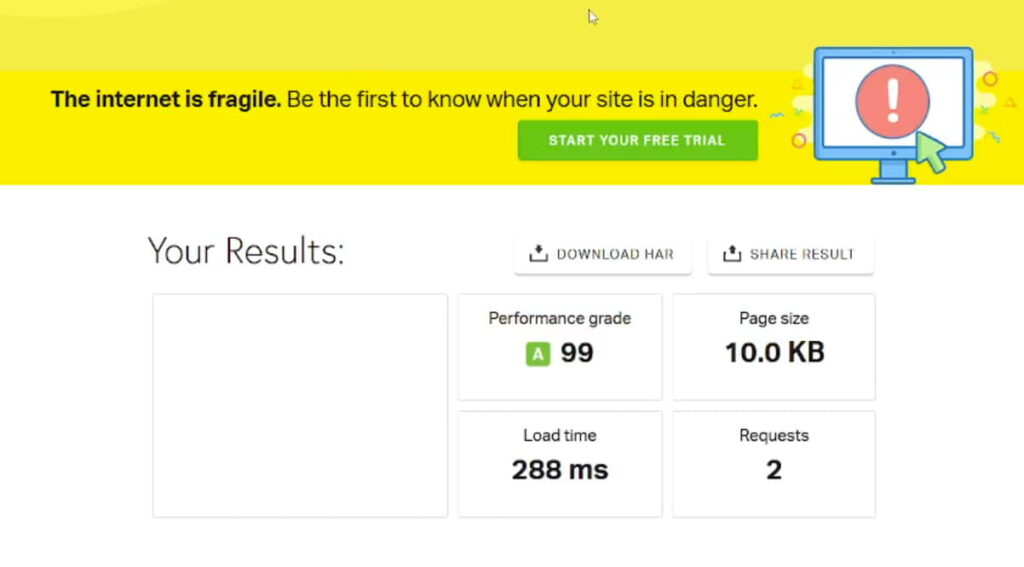
The system showed a very small downloaded page size and a completely blank screenshot. Yet, the server still responded with 200 OK.
This result clearly indicated that the page not included in the index was either not being sent to the checker or was being transmitted incorrectly. Moreover, the problem was not related to the server but had other causes that we could not understand since we did not develop this system and did not know what could be in the code.
Solving the Problem
The programmers began to investigate the page template and look for anything besides server settings and Cloudflare that could interfere with the page's correct serving. Eventually, they discovered that elements of the Elasticsearch search system were embedded in the "Publication" page templates, which were integrated to improve the site's internal search.
This system has its own bot protection and filtering system, which selectively triggers on certain bots, returning a white screen instead of page content while maintaining a 200 OK server response.
It was this protection that blocked the indexing of pages for the Google bot, while PageSpeed Insights, Google Microdata Checker, and the Google crawler (which checks page availability) passed without issues.
Since the decision to transmit the page was made on the site's backend, such an error was impossible to detect by simply comparing different types of pages. One had to encounter it in practice for the system to recognize the page request as a bot and serve an incorrect page.
Elasticsearch system elements that interfered with page loading were embedded only in certain content templates, such as Report and Post. This element was absent in post category templates, static pages, and tags, so they did not drop out of the index but were indexed as we removed duplicates and links to pages blocked from indexing.
After the programmers fixed this issue, pages began to index quite quickly. The fix affected not only the site's articles but also the fake news debunking section, where there was a similar problem.
Work Results
At the start of the audit, the client's site had 6,240 pages in the index, and they were gradually dropping out. There were no articles left in the index, and the occasional fact-checking reports that appeared to be indexed contained the error "Report not found" and were essentially duplicates of the page with this error. During the work and the step-by-step implementation of corrections, the number of pages not in the index slowly decreased and reached 2,711.
However, as soon as the main error was discovered and fixed, the indexing process accelerated significantly.
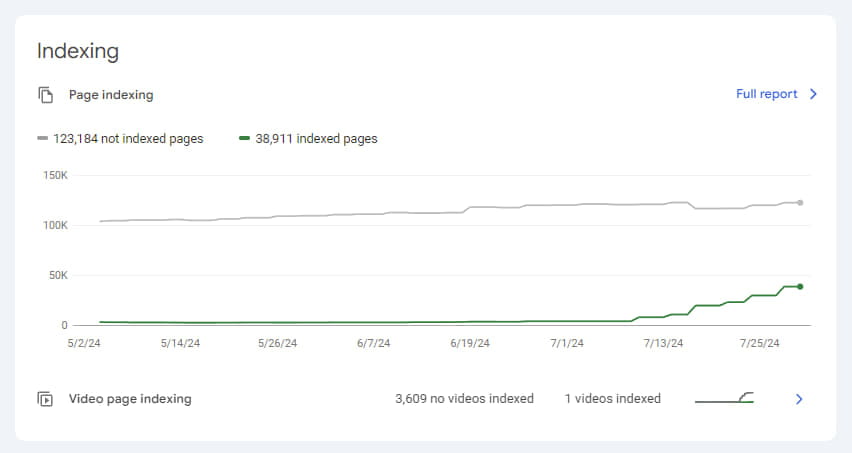
To further speed up indexing, we used the Google Indexing API, and in less than a month, we increased the number of indexed pages from the minimal level of 2,701 to 38,911. This also positively affected traffic.
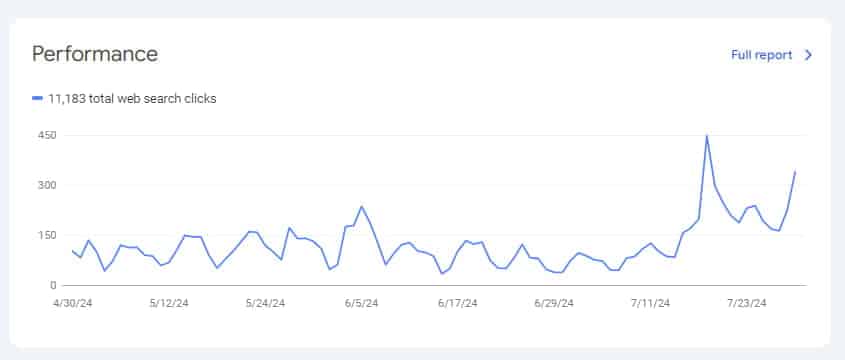
Of course, the project's indexing process is still ongoing and will take some time, but it is already clear that the main issue hindering indexing has been resolved.
This case clearly shows us how important deep technical understanding and a careful approach are when analyzing website indexing problems. Faced with an unusual situation where standard diagnostic methods did not reveal issues, our team managed to identify the root cause through a consistent approach and step-by-step problem-solving.
Our experience confirms that even the most complex problems can be solved with thorough analysis, persistence, teamwork, and the right choice of tools.