Розв’язання проблем з індексацією новинного сайту в Google
Розв'язання проблеми з індексацією багатомовного новинного сайту, чиї сторінки випадали з індексу упродовж шести місяців
Проєкт являє собою платформу новин, присвячену світовим подіям та фактчекінгу політичних і соціальних явищ. Платформа містить безліч сторінок, оскільки на старті сайт підтримував 8 мов, а зараз кількість зросло до 11. Всі матеріали унікальні та написані командою авторів. На сайті використовується багато тегів, а генерація контенту за допомогою ШІ не застосовується. Проєкт має численні зворотні посилання від новинних видань з усього світу. Проте за останній рік було відмічене зниження пошукового трафіку та масове випадання сторінок з індексу.
Знайти та усунути причину проблем з індексацією сторінок.
Стратегія
Клієнт раніше не займався просуванням сайту в пошукових системах, і весь SEO-трафік отримував природним шляхом. З якого моменту Google почав виключати сторінки з індексу, клієнт точно не знав. Процес відбувався поступово та тривалий час, без різких стрибків як у випаданні сторінок, так і в падінні трафіку. Проте була помітна чітка низхідна динаміка. На момент звернення до агентства в індексі залишалося менше 25% від загальної кількості сторінок на сайті.
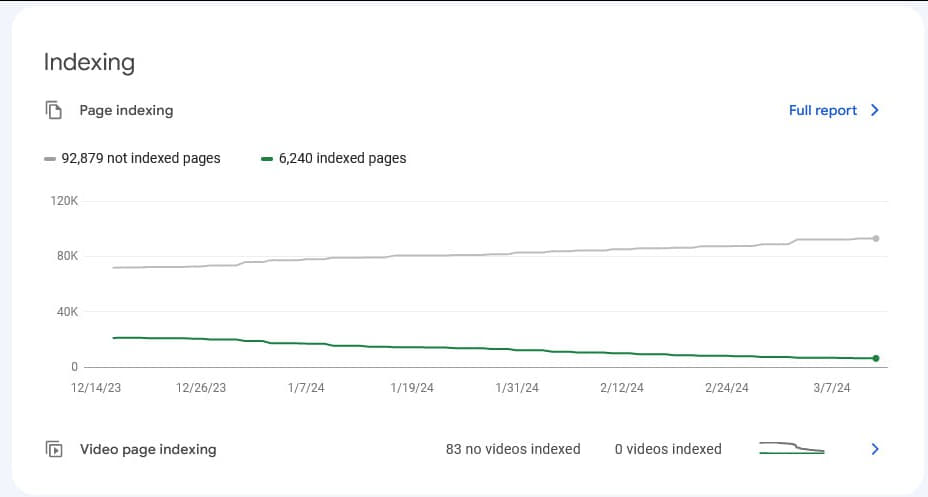
У кінці 2023 року клієнт звертався до одного з європейських агентств для проведення технічного аудиту. Однак на той момент проблем, які спостерігаються зараз, на сайті не було. Агентство надало рекомендації щодо виправлення технічних помилок, актуальних на момент того звернення, але було неясно, яку частину цих рекомендацій в результаті було впроваджено. З того часу сайт значно розширився, і фактично, потрібно було починати технічний аналіз з нуля.
Стратегія роботи
Згідно з даними Google Search Console, причина випадання сторінок з індексу не була очевидною. У звітах по індексації спостерігалася як поява нових URL в індексі, так і випадання раніше проіндексованих сторінок. При цьому не було ніяких ознак ручних фільтрів або явних проблем з доступом Google до сайту. Google Pagespeed Insights та Google Microdata Checker без проблем обробляли сторінки, навіть ті, що зникли з індексу. Сайт був побудований на WordPress, і сторінки віддавалися в Google у вигляді стандартного HTML-коду, що мало б сприяти успішній індексації, але на практиці виявилося навпаки.
Технічний аудит
В першу чергу ми провели аналіз сайту на предмет технічних помилок, і їх виявилося досить багато. У процесі аудиту ми зіткнулися з додатковими складнощами.
- На сайті була величезна кількість URL, і їх усі потрібно було передати в програму для сканування сайту. Це створювало велике навантаження на сервер, і при досягненні порогових значень клієнт був змушений зупиняти процес.
- Додатково на сайті був налаштований Cloudflare і захист хостингу від DDoS-атак, що також призводило до блокування SEO-сканера. Тому було вирішено вносити правки на сайт поетапно: чекати впровадження необхідних частин аудиту, потім повторно сканувати та проводити аудит ітеративно, оскільки через зазначені проблеми вдавалося просканувати не більше 10% сайту за раз.
Первинні результати аудиту
Редактори проєкту, що публікували контент, створювали в кожній статті безліч внутрішніх посилань на інші тематичні сторінки. Однак вони не мали достатніх знань про правильне формування URL на сайті. В результаті внутрішні посилання в статтях часто вели на:
- сторінки внутрішнього пошуку за ключовими словами;
- інші розділи та сторінки сайту, разом з сторінками з GET-параметрами, такими як ’highlight’, ’list’ або ’grid’, параметрами сортування тощо;
- сторінки внутрішнього пошуку з GET-параметром, що визначає тип контенту (сайт підтримував кілька типів контенту, і внутрішній пошук здійснювався окремо для кожного типу через відповідний GET-параметр);
- дубль-сторінки сайту без ’/’ в кінці, які були копіями оригінальних сторінок.
Крім того, на сайті було додано багато нестандартних функціональних елементів, які теоретично могли впливати на його роботу. Розплутування цього клубка проблем вимагало поетапного підходу, тим більше що все ускладнювалося тривалим процесом погодження з керівництвом проєкту. Без їхнього схвалення не можна було вносити жодних змін на робочий сайт.
Перша ітерація
Під час аналізу даних Google Search Console було виявлено, що Google переважно виключає з індексу статті з новинами та спростування фейкової інформації на тему ситуації в Україні (фактчекінг). При цьому він індексує багато дублікатів і сторінок, закритих від індексації.
Початкова гіпотеза на цьому етапі полягала в тому, що через великий обсяг "сміттєвого" контенту на сайті (численних посилань на сторінки, закриті від індексації, і великої кількості вихідних посилань з публікацій) внутрішня маса повилань сайту розподілялася некоректно. В результаті чого Google розглядав багато сторінок як неякісні і виключав їх з індексу. Інших припущень у нас не було, оскільки примусове надсилання сторінок в індекс не давало результатів, попри те, що Google не мав до них ніяких явних претензій.
Тому в першій ітерації було вирішено спочатку виправити код всіх публікацій на сайті, щоб усунути посилання на дублі та малокорисні сторінки. Оскільки такі сторінки зазвичай мали певні характеристики, посилання на них можна було виявити в коді сторінки. За допомогою спеціального скрипта програмісти просканували весь сайт, виявили подібні URL і склали таблицю з правками для коректування цих посилань.
Потім інший скрипт замінив некоректні посилання на правильні. Крім того, весь функціонал, який намагався віддавати боту посилання на сторінки з GET-параметрами відображення, сортування тощо, було заблоковано, щоб бот їх не бачив при скануванні.
Ця правка дозволила скоротити кількість URL, що віддавалися SEO-краулеру, і покращити сканування сайту. Також дане виправлення вплинуло на Google, який після цих змін став краще індексувати корисний контент і ігнорувати нерелевантний.
Друга ітерація
Правки першої ітерації не вирішили основну проблему проєкту, однак дозволили нам просунутися далі і приступити до наступного етапу робіт.
Функціонал тегування
Після повторного сканування сайту стала очевидна ще одна проблема: власники проєкту значно видозмінили WordPress, замінивши стандартний функціонал тегування на внутрішній пошук, який був закритий для індексації. Це означало, що у кожної статті був цілий ряд прикріплених тегів у вигляді посилань, які вели на сторінку внутрішнього пошуку з відповідним запитом. При цьому оригінальні сторінки тегів для бота віддавалися як порожні сторінки з білим екраном через карту сайту.
Тому наступним кроком стало повернення до вихідної системи тегування в WordPress, щоб кожен тег на сайті являв собою індексовану сторінку з чітким URL без GET-параметрів. Було прийнято рішення відмовитися від використання внутрішнього пошуку замість тегування.
Кнопки шерінгу контенту
Крім того, на сайті були вбудовані кнопки для шерінгу контенту, включаючи функціонал копіювання URL сторінки для вставки в iframe на сторонніх майданчиках. Це було впроваджено з маркетинговою логікою, схожою з даною:

Однак даний існтрументарій було реалізовано інакше: контент всіх сторінок публікацій дублювався на спеціальних полегшених сторінках, закритих від індексації, які вбудовувалися в iframe при використанні спеціального коду. Ці сторінки можна було переглядати в повному обсязі в маленькому вікні прямо на сторонній платформі. Не зважаючи на заборону індексації, Google періодично індексував такі сторінки, тоді як основні аналогічні сторінки залишалися не проіндексованими.
Тому було вирішено відмовитися від кнопки, яка надавала код для фрейму з посиланням на полегшену версію сторінки.
Перемикання мов
Додатково на цьому етапі було вирішено переглянути функціонал перемикання мов. Оскільки на сайті кожна мова мала різну кількість публікацій, клієнт використовував стандартний функціонал перемикання мов нестандартним чином. На кожну статтю виводилися посилання на інші мовні версії. Блок перемикання мов вів на ті сторінки, де був доступний переклад на відповідну мову, а у випадках відсутності перекладу посилання вели на головну сторінку сайту обраною мовою.
В результаті, через розширення кількості мов, у більшості випадків мовний перемикач на багатьох сторінках сайту посилався саме на головні сторінки інших мов.
Цей функціонал було вирішено переробити і закрити в скрипт, щоб боту не пропонувалися головні сторінки іншими мовами. Тим більше що головна сторінка проєкту збирала весь трафік за брендовим запитом, а не за загальними ключовими словами, важливими для SEO.
В результаті цієї ітерації кількість проблемних точок на сайті зменшилася, але основна проблема, з якою звернувся клієнт, все ще залишалася невирішеною.
Третя ітерація
Після двох етапів роботи у нас виникла нова гіпотеза: проблема може полягати в шаблонах тих сторінок, які випадають і не індексуються. Наприклад, тип сторінок "Публікація" випадав з індексу, тоді як статичні сторінки індексувалися без проблем. На додаток, сторінки типу "Звіт" індексувалися, навіть якщо вони містили помилку "Звіт не знайдено", оскільки такі сторінки не повертали серверну відповідь 404, а видавали 200 OK.
Перевірка різних шаблонів
Було прийнято рішення перевірити припущення на практиці. Було створено копію однієї з публікацій, і на ній по черзі відключалися різні елементи контенту: блоки перелінковки, внутрішні посилання, зображення. Однак сторінка публікації, навіть у полегшеній версії з одним лише текстом, так і не потрапила в індекс.
Тому було вирішено спробувати опублікувати контент однієї зі статей сайту з використанням іншого шаблону. Ми взяли одну статтю у вигляді чистого HTML і опублікували її не як звичайну сторінку в блозі (шаблон Post WordPress), а в шаблоні Page без жодних змін у відображенні. На цьому етапі стало очевидно, що сторінка з шаблоном Page і контентом статті, попри неідеальне відображення, була проіндексована. Водночас аналогічний контент у шаблоні Post не потрапив в індекс.
В обох випадках Google не висловлював претензій до сторінок і безперешкодно відвідував їх, що було видно в логах сервера.
Ми провели порівняння коду цих двох сторінок, щоб з'ясувати відмінності між версіями однієї і тієї ж сторінки, але нічого суттєвого в коді виявлено не було. Перевірки Google також не виявляли ніяких проблем з сайтом.
Проблеми зі швидкістю сторінок
Було прийнято рішення протестувати сторонні інструменти для аналізу сторінок і отримання рекомендацій. Ми спробували кілька варіантів, і тільки один з них показав незрозумілу проблему — при аналізі двох версій однієї і тієї ж публікації SiteChecker видав цікаві результати.
Сторінка на базі шаблону Page без проблем читалася цим інструментом, і система давала рекомендації щодо швидкості, оптимізації коду сторінки, підвантажувала метатеги і показувала вагу сторінки.
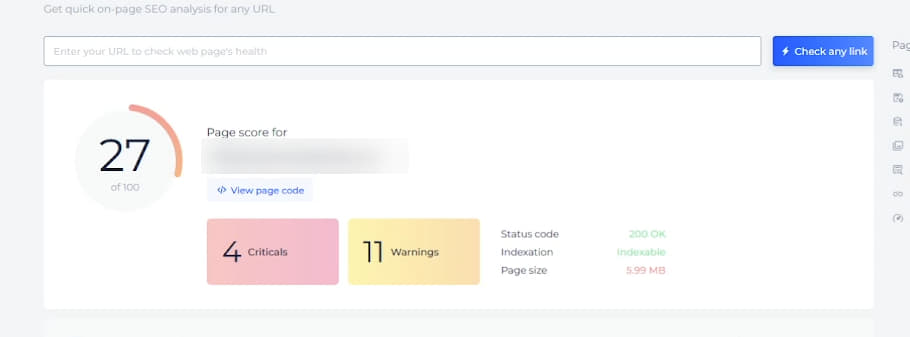
При цьому сторінка шаблону Post, яка не індексувалася, показувала розмір сторінки 0, метатеги не підвантажувалися, але при цьому рекомендації щодо оптимізації швидкості чекер видавав:
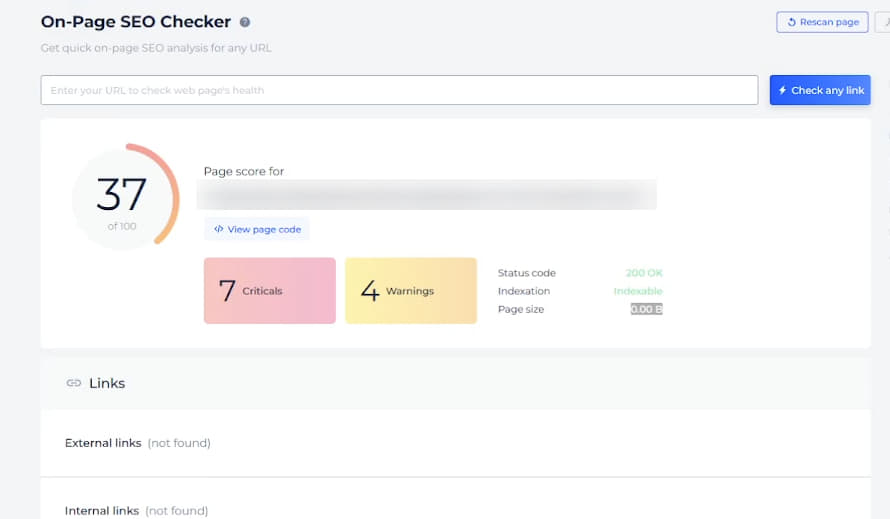
Причина подібного була незрозуміла, і підтримка інструменту теж не могла пояснити, в чому причина такої проблеми.
При аналізі було помічено, що показники швидкості завантаження у сторінок, які використовують шаблон Page, і шаблон Post сильно різняться. Для сторінок з шаблоном Post спостерігалася висока затримка сервера, що значно знижувало показники швидкості. На деяких сторінках статей швидкість за Pagespeed Insights була трохи більше ніж 20, а затримка сервера досягала 2-3 секунд, а іноді і більше.
Тому виникла гіпотеза, що через низьку швидкість завантаження сторінок новинного сайту, особливо через тривалу затримку сервера, Google можливо не дочікується повної передачі сторінки і йде. У зв'язку з цим було вирішено максимально прискорити сторінки, приділивши особливу увагу зниженню часу відгуку сервера і досягненню хоча б жовтих показників швидкості за Pagespeed Insights.
Для цього була проведена робота з сервером, налаштуваннями хмари Cloudflare і самим сайтом. Заради підвищення швидкості довелося тимчасово відключити частину функціонала, щоб розвантажити сторінки, наприклад, кнопки шерінгу і блок підвантаження контенту "Схожі публікації". Крім того, були замінені плагіни кешування сторінок і налаштовано багаторівневе кешування, оптимізовані зображення, стилі і скрипти.
В результаті програмістам проєкту спільно з хостинг-провайдером вдалося знайти оптимальну конфігурацію середовища для сайту і досягти більш прийнятних показників швидкості:
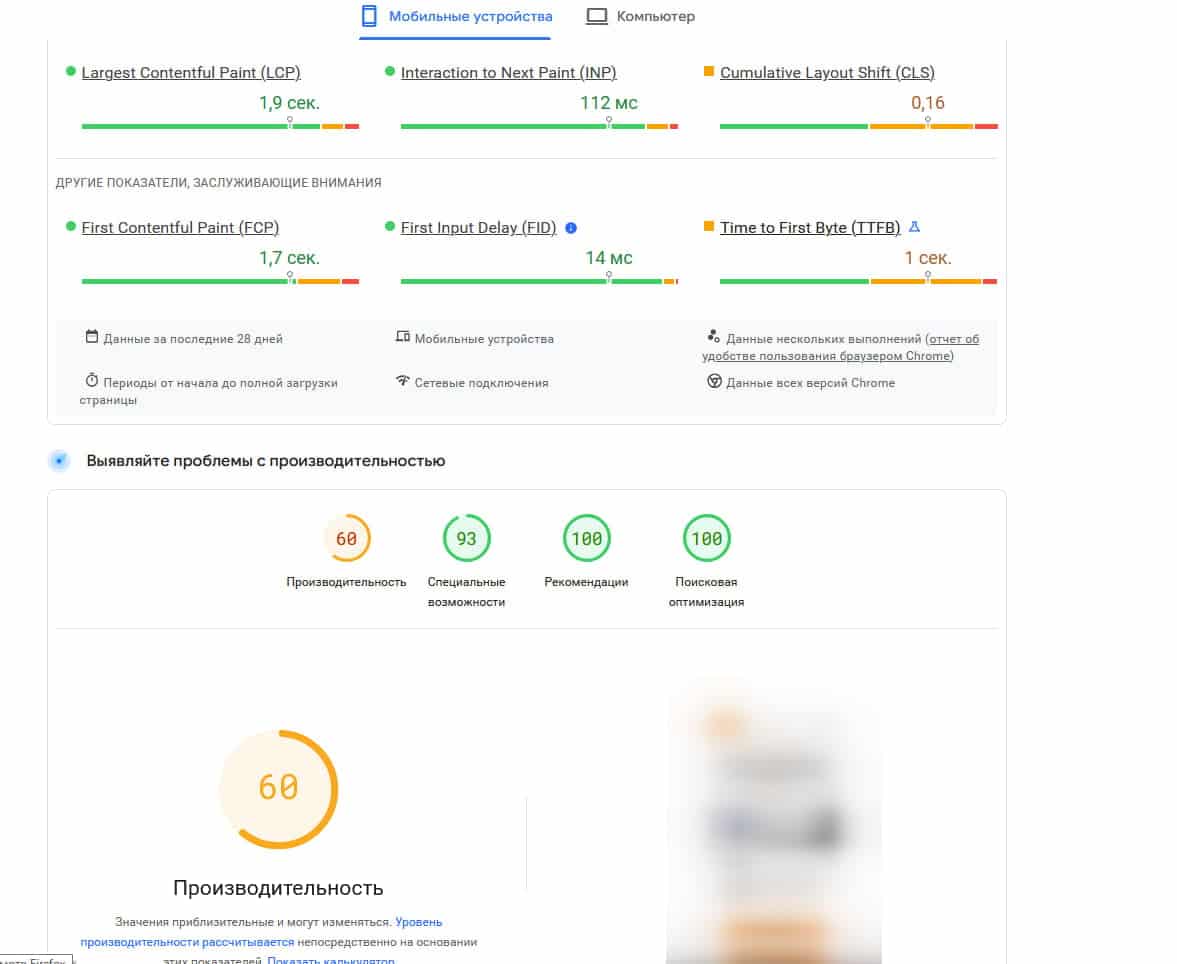
Після цих виправлень вдалося успішно проіндексувати кілька десятків сторінок через Google Search Console. Однак через два вихідні дні, коли було вирішено відправити на індексацію через Google Indexing API більшу кількість сторінок, Google їх в індекс не взяв. Надалі він не приймав жодну з наступних сторінок, ні при ручній переіндексації, ні через API. При цьому в Google Search Console знову не було ніяких помилок.
Четверта ітерація
На цьому етапі ми продовжили роботу з технічною стороною проєкту, зокрема зі швидкістю сторінок. Однак вирішили підійти трохи з іншого боку.
Аналіз коду і внутрішнього функціонала
Було вирішено порівняти код і внутрішній функціонал сторінок, які потрапили в індекс, і аналогічних сторінок, які Google відмовився брати в індекс.
За кодом все виявилося ідентичним, за винятком частини HTML-коду самої статті. Програмісти також підтвердили, що функціональних відмінностей не було. Тому ми обрали дві сторінки публікацій: одну, яка була в індексі, і іншу, яка не була, і відправили їх на аналіз за допомогою SiteChecker Free SEO Checker.
Звіт сервісу показав схожу картину: проіндексовані статті без проблем завантажувалися і аналізувалися, а у не проіндексованих – вага завантаженої сторінки залишалася 0.
Перевірка HTTP-заголовків теж не виявила ніяких відмінностей — вони були ідентичними для обох сторінок.
Ми перевірили сторінки також за допомогою інших аналізаторів, які в основному успішно проаналізували сторінки і не виявили проблем, за винятком різниці в показниках швидкості і часу відгуку сервера, які варіювалися від сторінки до сторінки. Виникла робоча гіпотеза, що сервер міг бути налаштований не зовсім коректно, що викликає нестабільність відгуку і проблеми з індексацією.
Однак, крім швидкості, чекери не надали корисної інформації, тому їх результати надалі не враховувалися.
На деякі чекери спрацював захист Cloudflare або хостера, і сервер повертав заборону у відповідь. Ці результати також довелося відкинути, оскільки аналогічних проблем у Google не спостерігалося, і на всіх коректних сторінках фіксувався відгук 200 OK. Але один з чекерів, Pingdom Website Speed Test, показав дуже дивну картину, яку ми в агентстві не знали, як інтерпретувати, і тому передали її на аналіз програмістам проєкту. Сторінки, які успішно індексувалися, мали цілком стандартний звіт:
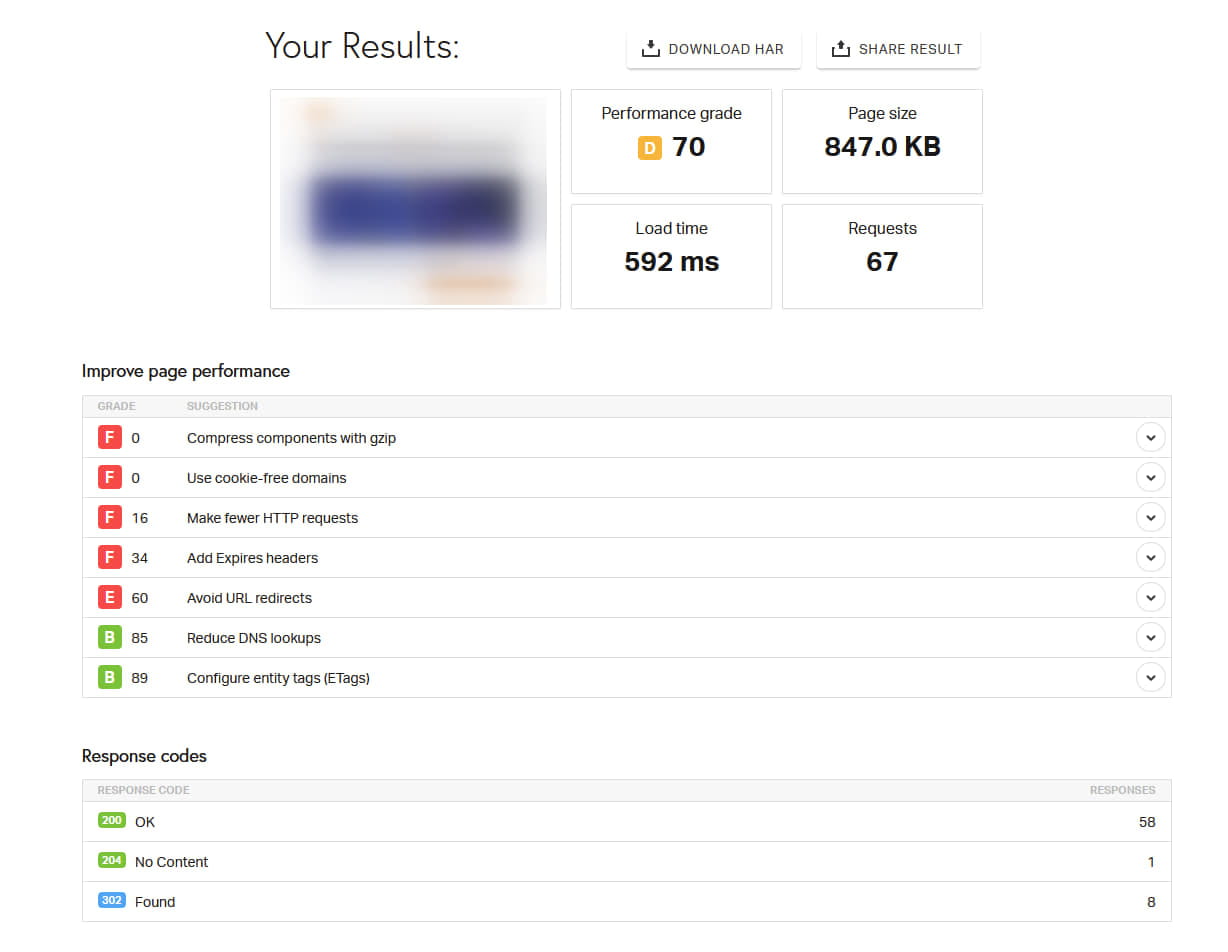
Тут видно показники завантаження, відповідь сервера і скріншот сторінки, яка завантажується.
При цьому сторінка, яка була не в індексі, мала ось такий звіт:
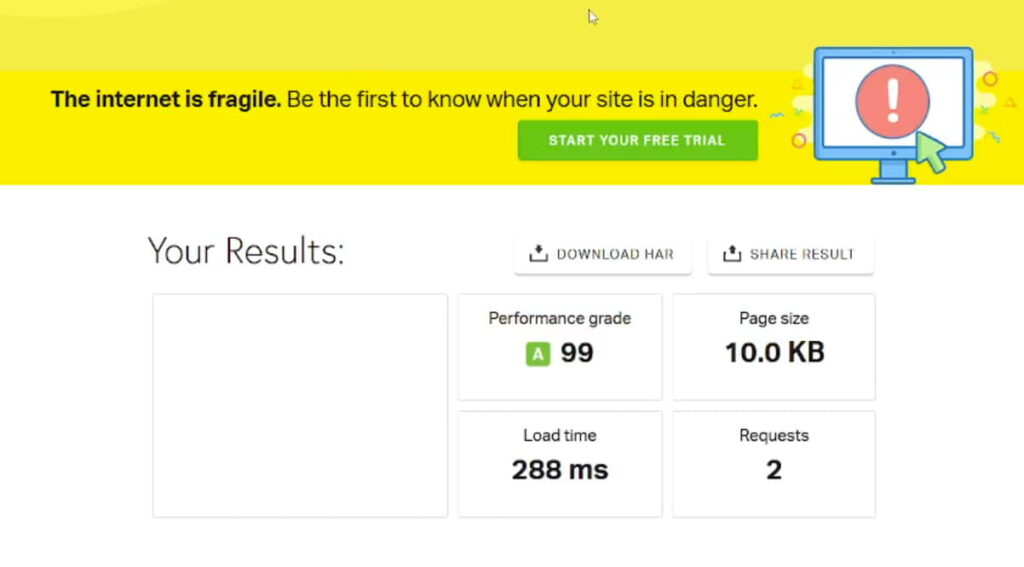
Система показувала дуже маленький обсяг завантаженої сторінки і повністю порожній скріншот. При цьому нижче в звіті сервер все одно відповідав 200 OK.
Це явно вказувало на те, що сторінка не потрапила в індекс або не віддавалася боту, чи передавалася некоректно. Причому проблема не була пов'язана з сервером, а мала інші причини, які ми не могли зрозуміти, оскільки не розробляли цю систему і не знали, що могло бути в коді.
Розв’язання проблеми
Програмісти почали детально розбиратися в шаблоні сторінки і шукати, що могло, окрім серверних налаштувань і Cloudflare, заважати коректному передаванню сторінки. В результаті вони виявили, що в шаблони сторінок "Публікація" були впроваджені елементи пошукової системи Elasticsearch, яка була інтегрована для покращення роботи внутрішнього пошуку на сайті.
У цієї системи є свій захист від ботів і система фільтрації, яка вибірково спрацьовує на деяких ботах, повертаючи білий екран замість контенту сторінки, при цьому зберігаючи відповідь сервера 200 OK.
Саме цей захист блокував індексацію сторінок для бота Google, тоді як Pagespeed Insights, Google Microdata Checker і краулер Google (який перевіряє доступність сторінки) проходили без проблем.
Оскільки рішення про віддавання сторінки приймалося на бекенд-стороні сайту, подібну помилку було неможливо виявити простим порівнянням різних типів сторінок. Потрібно було зіткнутися з нею в роботі, щоб система розпізнала запит до сторінки як бота і віддала некоректну сторінку.
Елементи пошукової системи Elasticsearch, які заважали завантаженню сторінок, були впроваджені тільки в певні шаблони контенту, такі як "Звіт" і "Post". В шаблонах категорій постів, статичних сторінках і тегах цей елемент був відсутній, тому вони не випадали з індексу, а навпаки, індексувалися в міру видалення дублікатів, посилань на закриті для індексації сторінки тощо.
Після того як програмісти усунули цю проблему, сторінки почали індексуватися досить швидко. Виправлення вплинуло не тільки на статті сайту, але і на розділ спростування фейкових новин, де була аналогічна проблема.
Результати роботи
На момент початку аудиту у клієнтського сайту було 6240 сторінок в індексі, і вони поступово випадали. В індексі не залишалося жодної статті, а ті звіти по фактчекінгу, які ще іноді траплялися, містили помилку "Звіт не знайдено" і фактично були дублікатами сторінки з цією помилкою. В процесі роботи і поетапного впровадження правок кількість сторінок не в індексі повільно зменшувалася і досягла 2711.
Однак, як тільки була виявлена і усунена основна помилка, процес індексації значно прискорився.
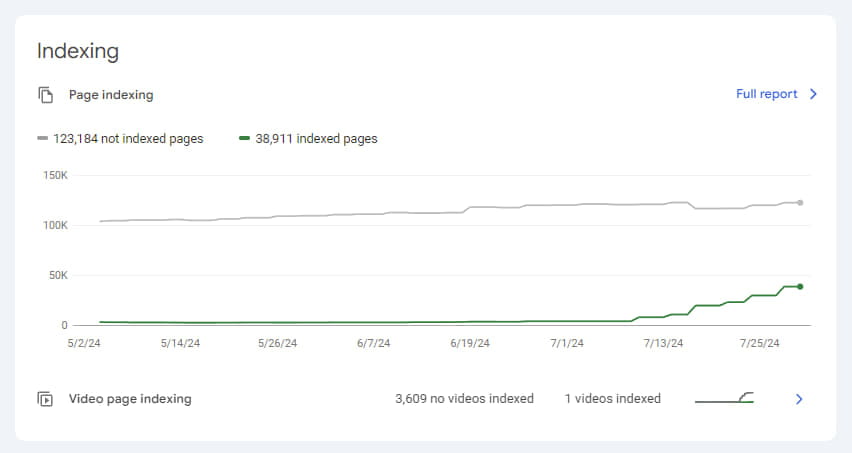
Щоб додатково прискорити індексацію, ми використовували Google Indexing API, і менш ніж за місяць нам вдалося збільшити кількість проіндексованих сторінок з мінімального рівня в 2711 до 38911. Це також позитивно позначилося на трафіку.
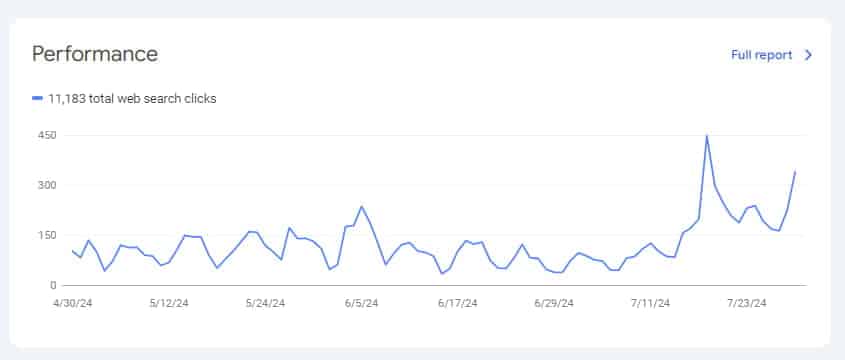
Звичайно, процес індексації проєкту ще продовжується і займе певний час, але вже видно, що основна проблема, яка заважала індексації, була усунена.
Цей кейс наочно демонструє, наскільки важливі глибоке технічне розуміння і уважний підхід до аналізу проблем з індексацією сайтів. Зіткнувшись з нестандартною ситуацією, де звичні методи діагностики не виявляли проблем, наша команда змогла визначити кореневу причину завдяки послідовному підходу і поетапному розв’язанню проблем.
Наш досвід підтверджує, що навіть найскладніші проблеми можна вирішити при ретельному аналізі, наполегливості, командній роботі і правильному виборі інструментів.